public String transfer(File file, String folderPath, String fileName) throws Exception { if (!opened) { throw new Exception("FileSystem was not opened!"); }
19/03/15 09:20:25 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Error parsing arguments for export: 19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: –input-null-string 19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: \N 19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: –input-null-non-string 19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: \N 19/03/15 09:20:25 ERROR tool.BaseSqoopTool: Unrecognized argument: –input-fields-terminated-by
解决方式 :命令输入错误,注意“-connect”应该是“–connect”杠
错误原因2
19/03/15 09:41:47 ERROR mapreduce.TextExportMapper: Exception: java.lang.RuntimeException: Can't parse input data: '2019春季新款chic条纹套头毛衣女装学生韩版宽松显瘦百搭长袖上衣,39.98,42.98,广东 广州,350' at commodity20190314.__loadFromFields(commodity20190314.java:487) at commodity20190314.parse(commodity20190314.java:386) at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:89)
java.lang.Exception: java.io.IOException: Can't export data, please check failed map task logs at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462) at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) Caused by: java.io.IOException: Can't export data, please check failed map task logs at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:122) at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146) at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:243) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
hive> select count(*) from commodity20190320; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. Query ID = root_20190320095041_1829fe55-336b-4481-a869-0b24ea274854 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Job running in-process (local Hadoop) 2019-03-20 09:50:43,908 Stage-1 map = 0%, reduce = 0% 2019-03-20 09:50:45,926 Stage-1 map = 100%, reduce = 0% 2019-03-20 09:50:46,936 Stage-1 map = 100%, reduce = 100% Ended Job = job_local1948148359_0001 MapReduce Jobs Launched: Stage-Stage-1: HDFS Read: 4150522476 HDFS Write: 0 SUCCESS Total MapReduce CPU Time Spent: 0 msec OK 14270481 Time taken: 6.276 seconds, Fetched: 1 row(s)
//查看表结构 hive> desc commodity20190320; OK affiliatedbasenum string locationid string pickupdate string dispatchingbasenum string Time taken: 0.044 seconds, Fetched: 4 row(s)
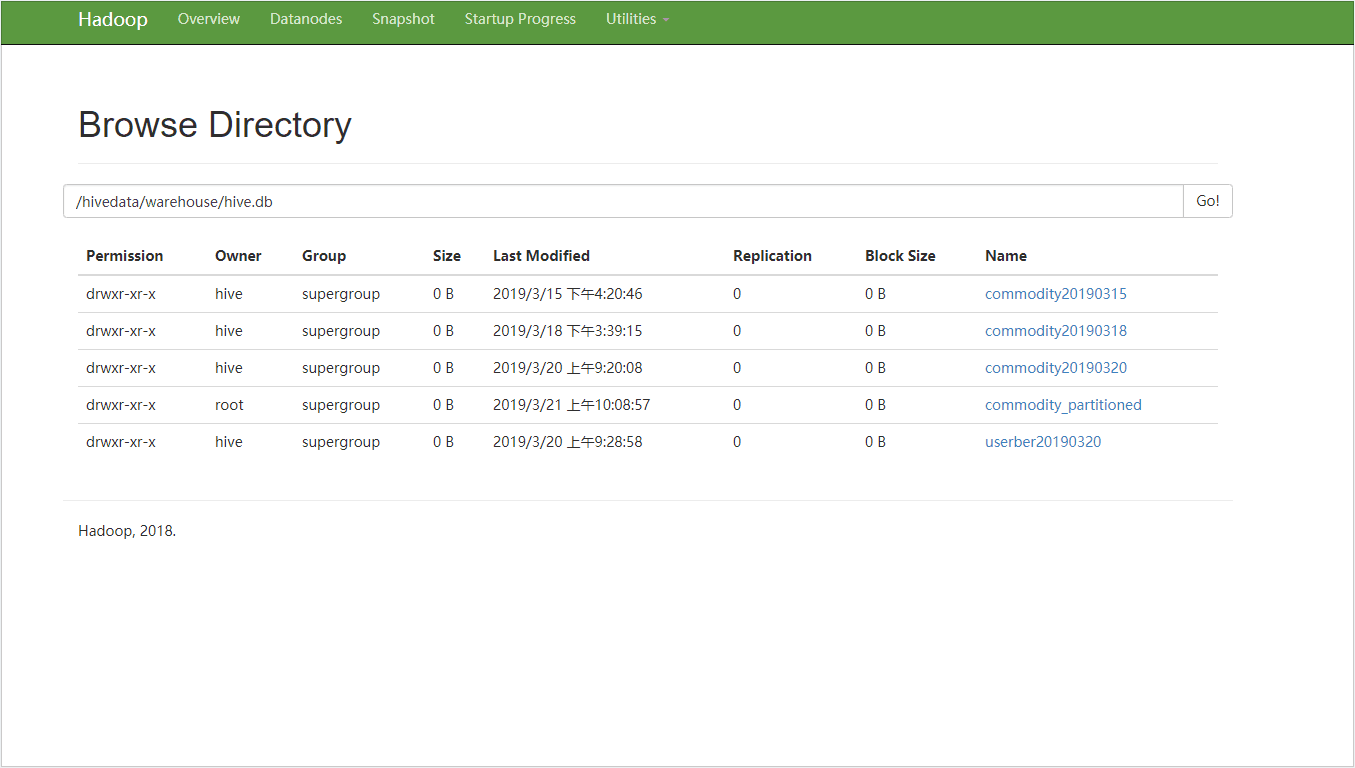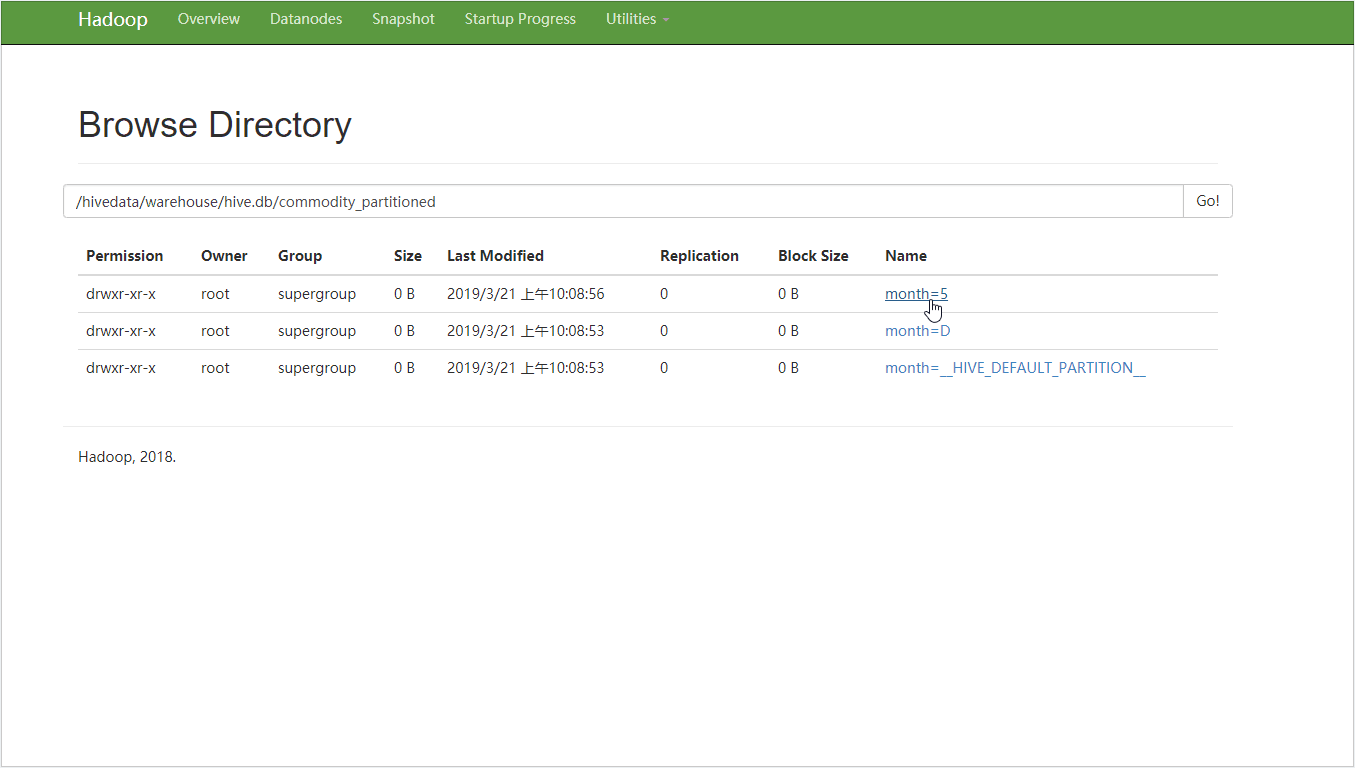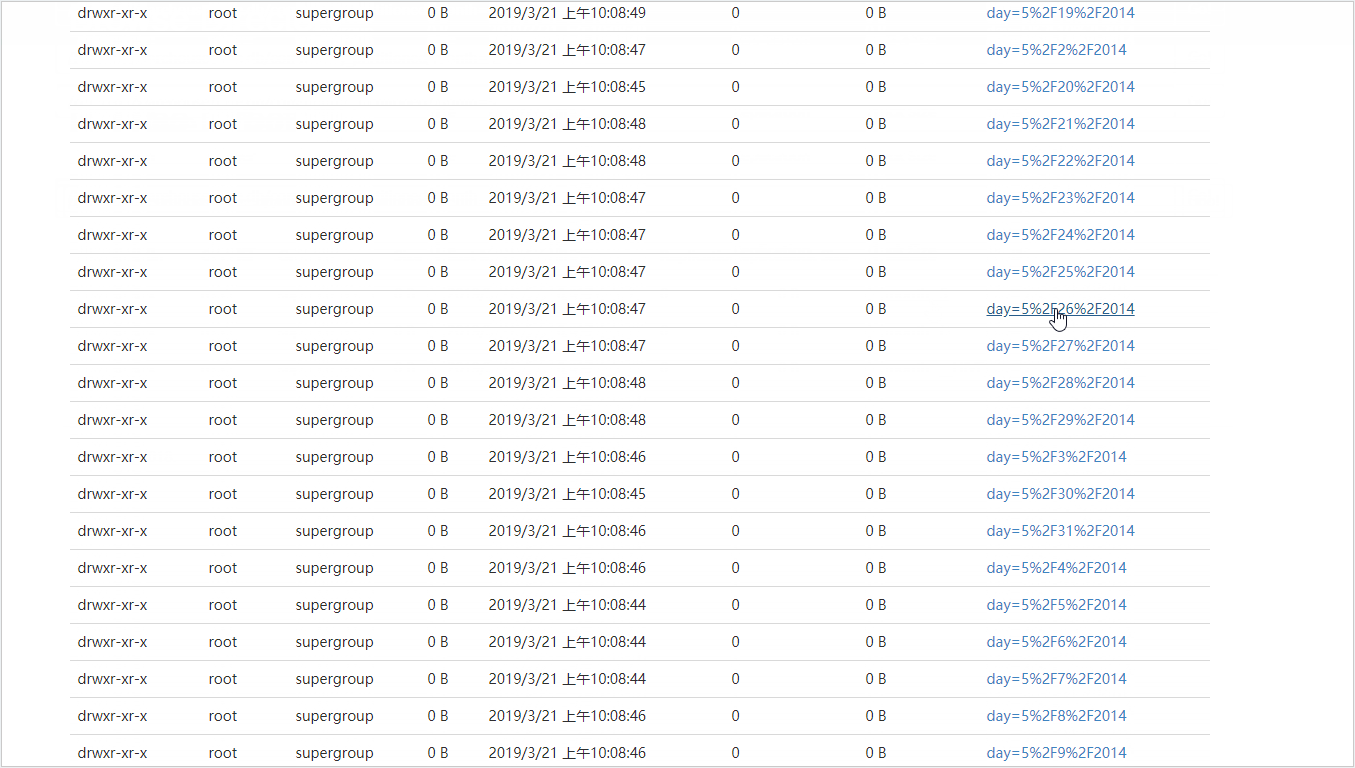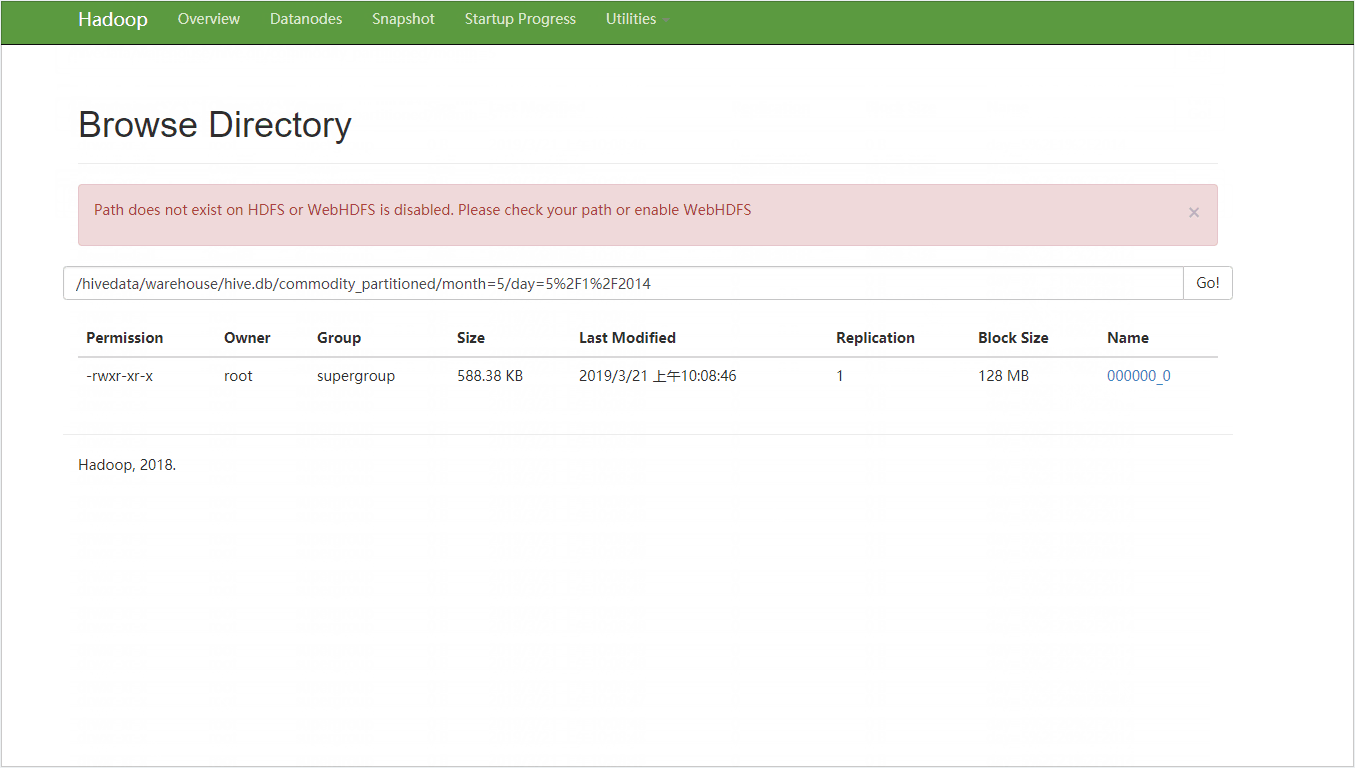
//创建按月按天分区表 hive> CREATE TABLE commodity_partitioned ( > affiliatedbasenum STRING, > locationid STRING, > dispatchingbasenum STRING > ) PARTITIONED BY (month STRING,day STRING) > stored AS textfile; OK Time taken: 0.238 seconds
//设置动态分区属性 hive> SET hive.exec.dynamic.partition=true; hive> SET hive.exec.dynamic.partition.mode=nonstrict; hive> SET hive.exec.max.dynamic.partitions.pernode = 1000; hive> SET hive.exec.max.dynamic.partitions=1000;
//时间格式 pickupdate = "5/31/2014 23:59:00" 按天分区则获取年月日即可。利用substr函数:substr(affiliatedbasenum,2,1) AS month,substr(affiliatedbasenum,2,9) AS day //向分区添加数据 hive> INSERT overwrite TABLE commodity_partitioned PARTITION (month,day) > SELECT locationid,pickupdate,dispatchingbasenum,substr(affiliatedbasenum,2,1) AS month,substr(affiliatedbasenum,2,9) AS day > FROM commodity20190320;